@property deftranspose(self): data = list(map(list, zip(*self.data))) return Matrix(data)
def_eye(self, n): return [[0if i != j else1for j inrange(n)] for i inrange(n)]
@property defeye(self): assert self.is_square, "The matrix has to be square!" data = self._eye(self.shape[0]) return Matrix(data)
def_gaussian_elimination(self, aug_matrix): n = len(aug_matrix) m = len(aug_matrix[0])
# From top to bottom. for col_idx inrange(n): # Check if element on the diagonal is zero. if aug_matrix[col_idx][col_idx] == 0: row_idx = col_idx # Find a row whose element has same column index with # the element on the diagonal is not zero. while row_idx < n and aug_matrix[row_idx][col_idx] == 0: row_idx += 1 # Add this row to the row of the element on the diagonal. for i inrange(col_idx, m): aug_matrix[col_idx][i] += aug_matrix[row_idx][i]
# Elimiate the non-zero element. for i inrange(col_idx + 1, n): # Skip the zero element. if aug_matrix[i][col_idx] == 0: continue # Elimiate the non-zero element. k = aug_matrix[i][col_idx] / aug_matrix[col_idx][col_idx] for j inrange(col_idx, m): aug_matrix[i][j] -= k * aug_matrix[col_idx][j]
# From bottom to top. for col_idx inrange(n - 1, -1, -1): # Elimiate the non-zero element. for i inrange(col_idx): # Skip the zero element. if aug_matrix[i][col_idx] == 0: continue # Elimiate the non-zero element. k = aug_matrix[i][col_idx] / aug_matrix[col_idx][col_idx] for j in chain(range(i, col_idx + 1), range(n, m)): aug_matrix[i][j] -= k * aug_matrix[col_idx][j]
# Iterate the element on the diagonal. for i inrange(n): k = 1 / aug_matrix[i][i] aug_matrix[i][i] *= k for j inrange(n, m): aug_matrix[i][j] *= k
return aug_matrix
def_inverse(self, data): n = len(data) unit_matrix = self._eye(n) aug_matrix = [a + b for a, b inzip(self.data, unit_matrix)] ret = self._gaussian_elimination(aug_matrix) returnlist(map(lambda x: x[n:], ret))
@property definverse(self): assert self.is_square, "The matrix has to be square!" data = self._inverse(self.data) return Matrix(data)
def_row_mul(self, row_A, row_B): returnsum(x[0] * x[1] for x inzip(row_A, row_B))
def_mat_mul(self, row_A, B): row_pairs = product([row_A], B.transpose.data) return [self._row_mul(*row_pair) for row_pair in row_pairs]
defmat_mul(self, B): error_msg = "A's column count does not match B's row count!" assert self.shape[1] == B.shape[0], error_msg return Matrix([self._mat_mul(row_A, B) for row_A in self.data])
def_mean(self, data): m = len(data) n = len(data[0]) ret = [0for _ inrange(n)] for row in data: for j inrange(n): ret[j] += row[j] / m return ret
defscala_mul(self, scala): m, n = self.shape data = deepcopy(self.data) for i inrange(m): for j inrange(n): data[i][j] *= scala return Matrix(data)
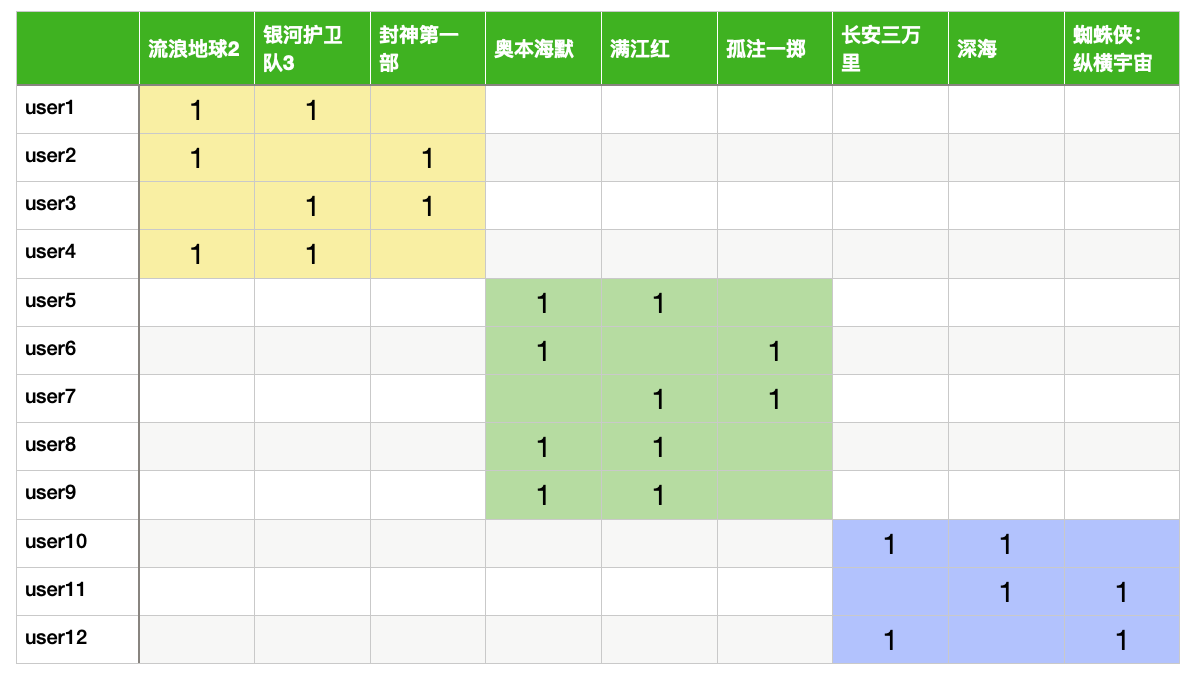
然后我们来创建一个读取数据的方法:
1 2 3 4 5 6 7 8
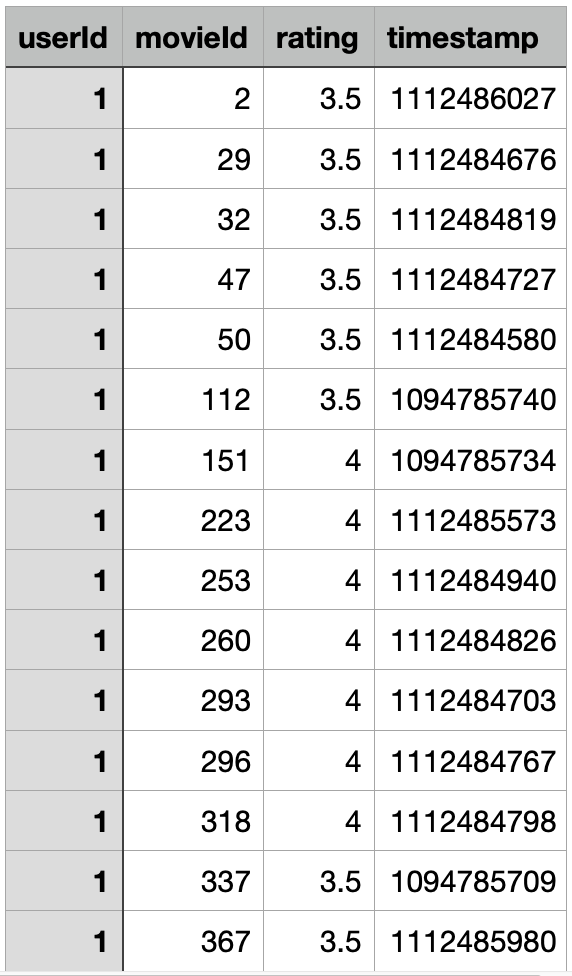
defload_movie_ratings(file): withopen(file) as ff: lines = iter(ff) col_names = ", ".join(next(lines)[:-1].split(",")[:-1]) data = [[float(x) if i == 2elseint(x) for i, x inenumerate(line[:-1].split(",")[:-1])] for line in lines] return data
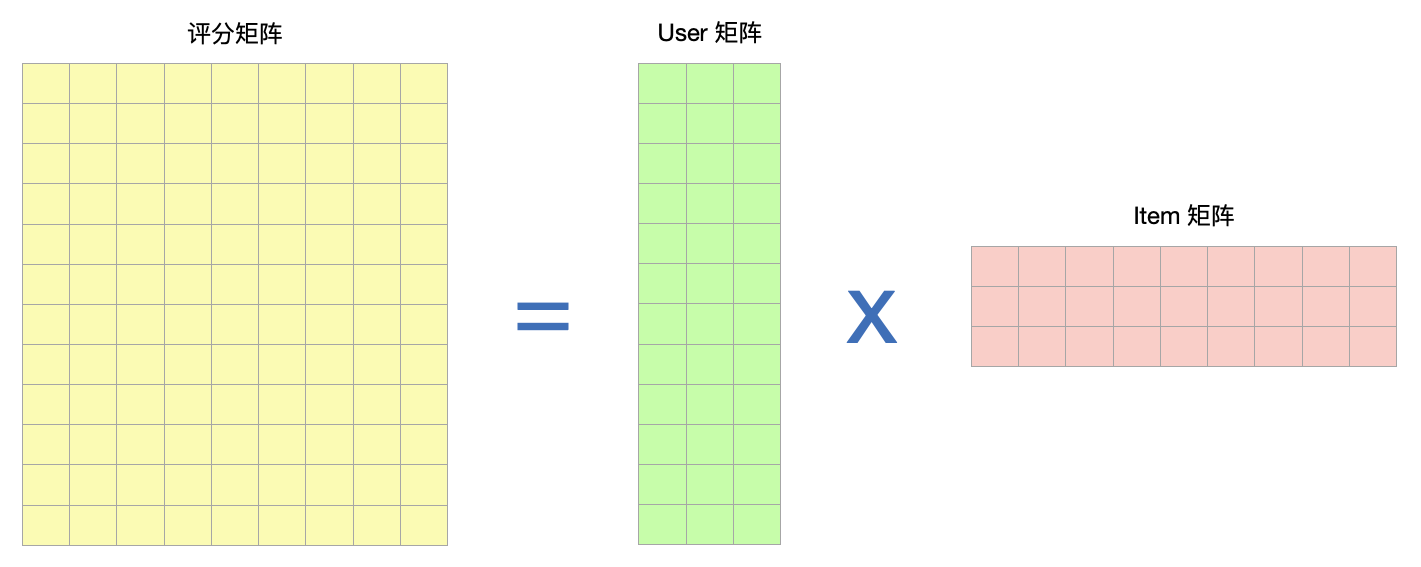
# 计算 RMSE def_get_rmse(self, ratings): m, n = self.shape mse = 0.0 n_elements = sum(map(len, ratings.values())) for i inrange(m): for j inrange(n): user_id = self.user_ids[i] item_id = self.item_ids[j] rating = ratings[user_id][item_id] if rating > 0: user_row = self.user_matrix.col(i).transpose item_col = self.item_matrix.col(j) rating_hat = user_row.mat_mul(item_col).data[0][0] square_error = (rating - rating_hat) ** 2 mse += square_error / n_elements return mse ** 0.5
# 模型训练 deffit(self, X, k, max_iter=10): ratings, ratings_T = self._process_data(X) self.user_items = {k: set(v.keys()) for k, v in ratings.items()} m, n = self.shape
error_msg = "Parameter k must be less than the rank of original matrix" assert k < min(m, n), error_msg
self.user_matrix = self._gen_random_matrix(k, m)
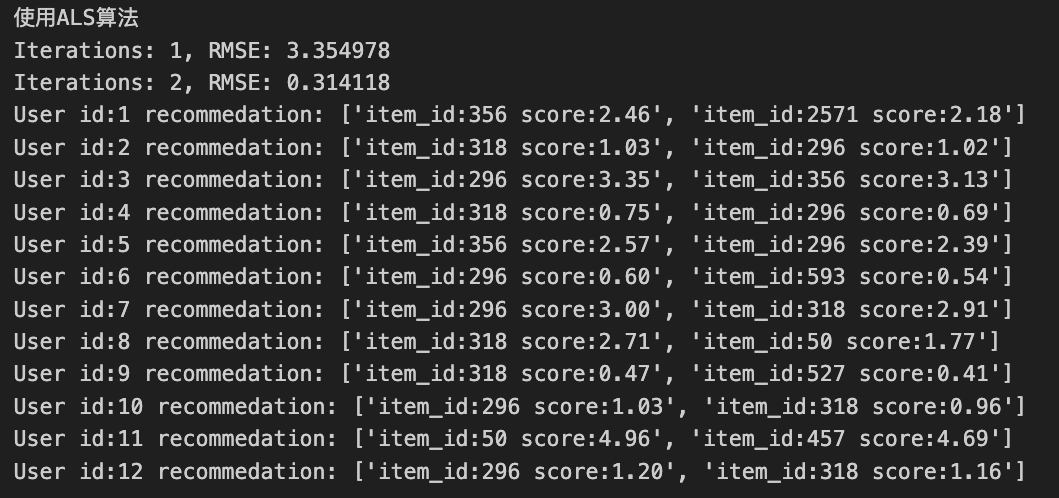
for i inrange(max_iter): if i % 2: items = self.item_matrix self.user_matrix = self._items_mul_ratings( items.mat_mul(items.transpose).inverse.mat_mul(items), ratings ) else: users = self.user_matrix self.item_matrix = self._users_mul_ratings( users.mat_mul(users.transpose).inverse.mat_mul(users), ratings_T ) rmse = self._get_rmse(ratings) print("Iterations: %d, RMSE: %.6f" % (i + 1, rmse))